우리가 통계관련 지식을 알지 못하면 이해하기 어려운 부분들이 많을 수 있으므로 일단 이해를 위해서 몇 가지 통계와 관련된 용어들에 대해 알아보자. 통계를 전부 다룬다기 보다(다룰 수도 없겠지만) 이런게 있구나 정도만 훓고 지나가자.
일단 다음 내용을 읽고 무슨 뜻인지 생각해보자.
"두 표본 집단의 특징값의 평균이 통계적으로 유의한 차이가 있는지 검증하자."
(ChatGPT에게 살짝 물어봤다.)
| 예를 들어, A와 B 두 집단의 키를 조사하여 비교한다고 가정해보자. 이때, A 집단의 평균 키가 170cm이고 B 집단의 평균 키가 175cm이라면, 두 집단의 키에 대한 평균값의 차이가 있는 것으로 보인다. 이러한 차이가 통계적으로 유의한지 검증하기 위해서는, t-검정을 사용할 수 있다. t-검정은 두 집단의 평균값의 차이가 우연에 의한 것인지 아니면 실제로 차이가 있는 것인지를 검증하는 방법이다. t-검정을 수행하기 위해서는, 먼저 두 집단의 표본 수, 평균값, 표준편차 등을 계산해야 한다. 이후에는 t-값을 계산하여 p-값을 구하고, 이 p-값이 유의수준(예를 들어, 0.05)보다 작으면 두 집단의 평균값의 차이가 통계적으로 유의미하다는 것을 의미한다. 결과를 도출하는 방법은, t-검정을 수행한 결과 t-값과 p-값을 확인하여, p-값이 유의수준보다 작으면 "두 집단의 평균값의 차이는 통계적으로 유의미하다"라는 결론을 내릴 수 있다. 반대로, p-값이 유의수준보다 크면 "두 집단의 평균값의 차이는 통계적으로 유의미하지 않다"라는 결론을 내릴 수 있다. |
아래 설명하는 내용은 YouTube의 "[R강의] 128. 엑셀 데이터 불러와서 통계량,그래프,t검정 하기 (템플릿)"의 내용을 따라하면서 정리한 것임을 밝힌다. 나중에 키와 몸무게 대신 다른 데이터로 변형할 것이다.)
우리는 2개반의 키와 몸무게를 30명씩 조사한 후 2개반의 평균을 구하고 통계적으로 유의한 차이가 있는지 확인해 보려고 한다.
1) R에 위의 엑셀 데이터를 읽어보자.
File - Import Dataset - From Excel 을 차례로 클릭하여 Import Excel Data 창을 실행시킨다.
엑셀 파일을 지정하고 아래 부분 Sheet에서 Default는 첫번째 있는 Sheet이므로 독립변수와 종속변수가 있는 R1 시트를 선택한다.

Import를 누르면 R Studio의 Console창에서만 실행되므로 다음에 재사용을 위해 Code Preview의 코드를 복사해서 스크립트 창에 붙여넣는다. 아래와 같이 EXCEL_R_data는 파일이름이 너무 길므로 작업하기 쉽게 dt로 바꿔 놓고, View는 필요없으니 지워주고 붙여 넣자.
| library(readxl) dt <- read_excel("C:/Users/82108/Downloads/EXCEL_R_data.xlsx", sheet = "R1") |
dt를 입력하고 실행하면 tibble형태로 되어 있다. 작업의 편의를 위해 dataframe으로 바꿔주자.
dt = as.data.frame(dt)
str(dt) # 구조를 확인하면 변경된 것을 알 수 있다.
2) 그래프를 그려보자.
독립변수는 범주형, 종속 변수는 수치형으로 되어 있는 경우 그리기 좋은 그래프는 boxplot, histgram 등이 있는데 분포를 보려는 것이 아니고 두반의 키와 몸무게를 비교하는 것이 목적이므로 boxplot을 사용하도록 한다.
boxplot은 boxplot(종속변수~독립변수, 데이터)로도 그려진다.
키가 종속변수, 반이 종속변수인 boxplot을 그려보자.
boxplot(키~반,dt)

그래프가 나오기는 했는데 오른쪽 상단에 동그라미같은 이상한 값이 있다. 입력데이터가 잘못된 것인데 이렇게 박스플롯의 장점은 한눈에 이런 이상한 데이터를 찾아내는데 유용하다는 것이다. 이상치라고 판단되는 것을 동그라미로 표시하는 것이다. 위의 그래프로 보면 키가 15미터를 넘는 경우는 없을 것이다.
몸무게가 종속변수, 반이 종속변수인 boxplot을 다시 그려보자.
boxplot(몸무게~반,dt)

화면을 분할해서 두 행중 왼쪽과 오른쪽에 나타내기 위해 boxplot을 그리기 전에 par(mfrow=c(1,2))를 먼저 실행시킨다.

이상치 값을 Excel 데이터에서 찾아 찾아 1666을 166으로 수정한 후 저장하고 다시 처음부터 동일한 작업을 수행해보자. 우리는 스크립트에서 작업을 수행했기 때문에 쉽게 작업할 수 있다.
그러면 아래와 같이 이상치가 사라진 그래프를 얻을 수 있을 것이다.

그래프 결과 A반이 키가 더 크고 몸무게도 더 많이 나가는 것으로 확인되었다. 그러면 우리가 처음에 얘기했던 통계적으로 유의한가에 대한 생각을 해보자.
3) 통계량을 구해보자.
통계량은 평균±표준편차(최솟값, 최댓값) 처럼 나타내려고 하는데 이런 형태는 논문에서 많이 표현하는 형태라고 한다. 이렇게 표현하려면 함수를 여러개 써야 하고 수식이 복잡하다. 미리 함수를 만들어 놓으면 나중에 필요할 때 가져다 쓰면 되겠다.
그리고 우리가 표현하려고 하는 것은 다음과 같은 표이다.
| A | B | P-value | |
| 키 | D11 | D12 | D13 |
| 몸무게 | D21 | D22 | D23 |
여기에서는 Mean, SD, Min, Max값을 의미하는 MSMM이라는 이름의 함수를 만들었다.
| MSMM = function(my_data, decimal) { m=round(mean(my_data,na.rm=TRUE),decimal) # 평균에 결측값제거하고 소수점 decimal자릿수 만큼... sd=round(sd(my_data,na.rm=TRUE),decimal) # 분산에 min=round(min(my_data,na.rm=TRUE),decimal) max=round(max(my_data,na.rm=TRUE),decimal) result=paste0(m,"±",sd," ","(",min,",",max,")") # 평균±표준편차(최솟값, 최댓값)처럼나타내기 print(result) } |
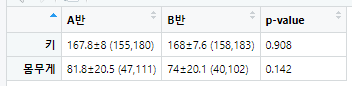
D11 = MSMM(dt[dt['반']=='A', '키'],decimal=1) #이렇게 입력하면 167.8±8 (155,180) 이와 같은 결과를 얻을 수 있다.
D12=MSMM(dt[dt['반']=="B",'키'],decimal=1) #이렇게 입력하면 168±7.6 (158,183) 이와 같은 결과를 얻을 수 있다.
D21=MSMM(dt[dt['반']=="A",'몸무게'],decimal=1) #이렇게 입력하면 81.8±20.5 (47,111) 이와 같은 결과를 얻을 수 있다.
D22=MSMM(dt[dt['반']=="B",'몸무게'],decimal=1) #이렇게 입력하면 74±20.1 (40,102) 이와 같은 결과를 얻을 수 있다.
t검정은 D13과 D23에 키 t검정 p값과 몸무게 t검정 p값을 넣는다.
D13=round(t.test(키~반,dt)$p.value,3) #이렇게 입력하면 0.908 값이 D13에 저장됩니다.
D23=round(t.test(몸무게~반,dt)$p.value,3) #이렇게 입력하면 0.142 값이 D223에 저장됩니다.
4) 표 만들기
R1=c(D11,D12,D13)
R2=c(D21,D22,D23)
re_tab=rbind(R1,R2)
colnames(re_tab)=c("A반","B반","p-value")
rownames(re_tab)=c("키","몸무게")
View(re_tab)
전체 코드는 다음과 같다.
| library(readxl) dt <- read_excel("C:/Users/82108/Downloads/EXCEL_R_data.xlsx", sheet = "R1") dt = as.data.frame(dt) par(mfrow=c(1,2)) boxplot(키~반,dt) boxplot(몸무게~반,dt) MSMM = function(my_data, decimal) { m=round(mean(my_data,na.rm=TRUE),decimal) # 평균에 결측값제거하고 소수점 decimal자릿수 만큼... sd=round(sd(my_data,na.rm=TRUE),decimal) # 분산에 min=round(min(my_data,na.rm=TRUE),decimal) max=round(max(my_data,na.rm=TRUE),decimal) result=paste0(m,"±",sd," ","(",min,",",max,")") # 평균±표준편차(최솟값, 최댓값)처럼나타내기 print(result) } D11 = MSMM(dt[dt['반']=='A', '키'],decimal=1) D12 = MSMM(dt[dt['반']=="B",'키'],decimal=1) D21 = MSMM(dt[dt['반']=="A",'몸무게'],decimal=1) D22 = MSMM(dt[dt['반']=="B",'몸무게'],decimal=1) round(t.test(키~반,dt)$p.value,3) round(t.test(몸무게~반,dt)$p.value,3) R1=c(D11,D12,D13) R2=c(D21,D22,D23) re_tab=rbind(R1,R2) colnames(re_tab)=c("A반","B반","p-value") rownames(re_tab)=c("키","몸무게") View(re_tab) |
결론적으로 키의 P-value가 0.908이므로, 유의수준 0.05에서 검정했을 때 귀무가설(두 반의 키는 차이가 없다)을 기각할 수 없다. 따라서, 통계적으로 유의한 차이가 없다는 결론을 내릴 수 있다.
반면에, 몸무게의 P-value가 0.142이므로, 유의수준 0.05에서 검정했을 때 귀무가설(두 반의 몸무게는 차이가 없다)을 기각할 수 없다. 따라서, 통계적으로 유의한 차이가 없다는 결론을 내릴 수 있다.
즉, 두 반의 키와 몸무게는 통계적으로 유의한 차이가 없다는 결론을 내릴 수 있다.
참고로 P-value만으로 어떤 결정하는 것은 위험하다. P-value는 검정통계량이 귀무가설에서 발생할 확률을 나타내는 지표이므로, 다른 요인들과 함께 고려하여 해석해야 한다. 따라서, P-value를 해석할 때는 유의수준, 검정통계량, 샘플 크기, 가설 설정 등 다양한 요인들을 함께 고려해야 한다.
'언어 > R' 카테고리의 다른 글
| 빅데이터 자격증 (0) | 2023.06.06 |
|---|---|
| Shiny for R (0) | 2023.05.30 |
| [R-012] R - markdown (0) | 2023.05.14 |
| [R-011] ggplot2 - geom_bar() (0) | 2023.05.05 |
| [R-010] ggplot2 - geom_point() (0) | 2023.05.03 |



댓글